Migrating applications to AWS, even without significant changes (an approach known as lift and shift), provides organizations with the benefits of a secure and cost-efficient infrastructure. However, to make the most of the elasticity and agility that are possible with cloud computing, engineers have to evolve their architectures to take advantage of AWS capabilities.
For new applications, cloud-specific IT architecture patterns can help drive efficiency and scalability. Those new architectures can support anything from real-time analytics of internet-scale data to applications with unpredictable traffic from thousands of connected Internet of Things (IoT) or mobile devices. That's why we decided to move to AWS.
Differences Between Traditional and Cloud Computing Environments
On AWS, servers, databases, storage, and higher-level application components can be instantiated within seconds. Our Team can treat these as temporary resources, free from the inflexibility and constraints of a fixed and finite IT infrastructure. This resets the way Our Team approaches change management, testing, reliability, and capacity planning. This change in approach encourages experimentation by introducing the ability of processes to fail fast and iterate quickly.
Global, Available, and Scalable Capacity
Using the global infrastructure of AWS, Our Team can deploy RentOptimum to the AWS Region that best meets Our requirements (e.g., proximity to Our end users, compliance, data residency constraints, and cost).3 For global applications, We reduce latency to end-users around the world by using the Amazon CloudFront content delivery network (CDN). This also makes it much easier to operate production applications and databases across multiple data centers to achieve high availability and fault tolerance. The global infrastructure of AWS and the ability to provision capacity as needed let Our Team think differently about Our infrastructure as the demands on Our applications and the breadth of Our services expand.
Higher-Level Managed Services
Apart from the compute resources of Amazon Elastic Compute Cloud (Amazon EC2), We also have access to a broad set of storage, database, analytics, application, and deployment services. Because these services are instantly available to developers, they reduce dependency on in-house specialized skills and allow organizations to deliver new solutions faster. AWS services that are managed can lower operational complexity and cost. They are also designed for scalability and high availability, so they can reduce risk for Our implementations.
Built-in Security
In traditional IT environments, infrastructure security auditing can be a periodic and manual process. In contrast, the AWS Cloud provides governance capabilities that enable continuous monitoring of configuration changes to Our IT resources. Security at AWS is the highest priority, which means that We benefit from data centers and network architecture that are built to meet the requirements of the most security-sensitive organizations.
Since AWS resources are programmable using tools and APIs, We formalize and embed Our security policy within the design of Our infrastructure. With the ability to spin up temporary environments, security testing can now become part of Our continuous delivery pipeline. Finally, We leverage a variety of native AWS security and encryption features that can help Us achieve higher levels of data protection and compliance.
Architecting for Cost
Traditional cost management of on-premises solutions is not typically tightly coupled to the provision of services. When We provision a cloud computing environment, optimizing for cost is a fundamental design tenant for architects. When selecting a solution, We should not only focus on the functional architecture and feature set but on the cost profile of the solutions, We select.
AWS provides fine-grained billing, which enables Us to track the costs associated with all aspects of Our solutions. There is a range of services to help us manage budgets, alert Us to costs incurred, and help us optimize resource usage and costs.
Design Principles
The AWS Cloud includes many design patterns and architectural options that We apply to a wide variety of use cases. Some key design principles of the AWS Cloud include scalability, disposable resources, automation, loose coupling managed services instead of servers, and flexible data storage options.
Scalability
Systems that are expected to grow over time need to be built on top of a scalable architecture. Such an architecture can support growth in users, traffic, or data size with no drop-in performance. It should provide that scale in a linear manner where adding extra resources results in at least a proportional increase inability to serve additional load. Growth should introduce economies of scale, and cost should follow the same dimension that generates business value out of that system. While cloud computing provides virtually unlimited on-demand capacity, Our design needs to be able to take advantage of those resources seamlessly.
There are generally two ways to scale an IT architecture: vertically and horizontally.
Scaling Vertically
Scaling vertically takes place through an increase in the specifications of an individual resource, such as upgrading a server with a larger hard drive or a faster CPU. With Amazon EC2, We stop an instance and resize it to an instance type that has more RAM, CPU, I/O, or networking capabilities. This way of scaling can eventually reach a limit, and it is not always a cost-efficient or highly available approach. However, it is very easy to implement and can be sufficient for many use cases especially in the short term.
Scaling Horizontally
Scaling horizontally takes place through an increase in the number of resources, such as adding more hard drives to a storage array or adding more servers to support an application. This is a great way to build internet-scale applications that leverage the elasticity of cloud computing. Not all architectures are designed to distribute their workload to multiple resources, so let’s examine some possible scenarios.
Stateless Applications
When users or services interact with an application they will often perform a series of interactions that form a session. A session is unique data for users that persists between requests while they use the application. A stateless application is an application that does not need knowledge of previous interactions and does not store session information. For example, an application that, given the same input, provides the same response to any end-user, is a stateless application. Stateless applications can scale horizontally because any of the available compute resources (such as EC2 instances and AWS Lambda functions) can service any request. Without stored session data, We simply add more compute resources as needed. When that capacity is no longer required, We safely terminate those individual resources, after running tasks have been drained. Those resources do not need to be aware of the presence of their peers—all that is required is a way to distribute the workload to them.
Distribute Load to Multiple Nodes
To distribute the workload to multiple nodes in Our environment, We choose either a push or a pull model.
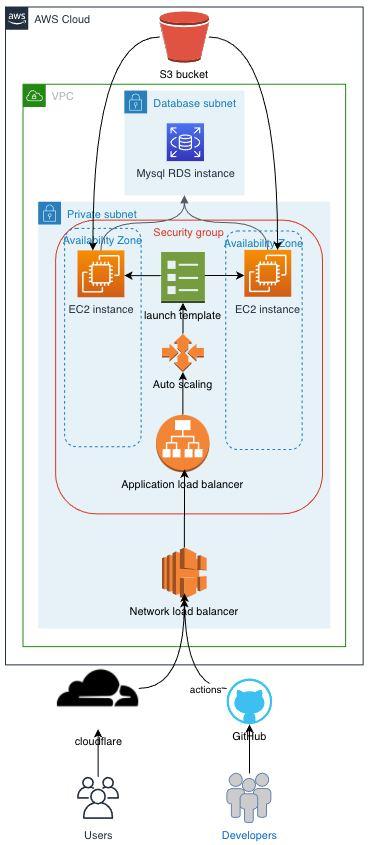
With a push model, We use Elastic Load Balancing (ELB) to distribute a workload. ELB routes incoming application requests across multiple EC2 instances. When routing traffic, a Network Load Balancer operates at layer 4 of the Open Systems Interconnection (OSI) model to handle millions of requests per second. With the adoption of container-based services, We also use an Application Load Balancer. An Application Load Balancer provides Layer 7 of the OSI model and supports content-based routing of requests based on application traffic. Alternatively, We use Amazon Route 53 to implement a DNS round robin. In this case, DNS responses return an IP address from a list of valid hosts in a round-robin fashion. While easy to implement, this approach does not always work well with the elasticity of cloud computing. This is because even if We set low time to live (TTL) values for Our DNS records, caching DNS resolvers is outside the control of Amazon Route 53 and might not always respect Our settings.
Stateless Components
In practice, most applications maintain some kind of state information. For example, web applications need to track whether a user is signed in so that personalized content can be presented based on previous actions. An automated multi-step process also needs to track previous activity to decide what its next action should be. We still make a portion of these architectures stateless by not storing anything that needs to persist for more than a single request in the local file system.
For example, web applications can use HTTP cookies to store session information (such as shopping cart items) in the web client cache. The browser passes that information back to the server at each subsequent request so that the application does not need to store it. However, this approach has two drawbacks. First, the content of the HTTP cookies can be tampered with on the client-side, so We should always treat it as untrusted data that must be validated. Second, HTTP cookies are transmitted with every request, which means that We should keep their size to a minimum to avoid unnecessary latency.
Consider only storing a unique session identifier in an HTTP cookie and storing more detailed user-session information on the server-side. Most programming platforms provide a native session management mechanism that works this way. However, user-session information is often stored on the local file system by default and results in a stateful architecture. A common solution to this problem is to store this information in a database. Amazon DynamoDB is a great choice because of its scalability, high availability, and durability characteristics. For many platforms, there are open source drop-in replacement libraries that allow Us to store native sessions in Amazon DynamoDB.4
Other scenarios require storage of larger files (such as user uploads and interim results of batch processes). By placing those files in a shared storage layer such as Amazon Simple Storage Service (Amazon S3) or Amazon Elastic File System (Amazon EFS), We avoid the introduction of stateful components.
Infrastructure as Code
The application of the principles we have discussed does not have to be limited to the individual resource level. Because AWS assets are programmable, We can apply techniques, practices, and tools from software development to make Our whole infrastructure reusable, maintainable, extensible, and testable. For more information, see the Infrastructure as Code whitepaper.15
Terraform templates give Us an easy way to create and manage a collection of related AWS resources, and provision and update them in an orderly and predictable fashion. We can describe the AWS resources and any associated dependencies or runtime parameters required to run Our application. Our CloudFormation templates can live with RentOptimum in Our version control repository, which allows Us to reuse architectures and reliably clone production environments for testing.
Automation
In a traditional IT infrastructure, We often have to manually react to a variety of events. When deploying on AWS, there is an opportunity for automation, so that We improve both Our system’s stability and the efficiency of Our organization. Consider introducing one or more of these types of automation into RentOptimum architecture to ensure more resiliency, scalability, and performance.